Job Results from RES Automation Manager
Often it is interesting, sometimes necessary, to do some analysis of the tasks you ran on your machines using RES AM. If everything went right, you can click around a little, but for more serious analysis and reporting you need data, not colorful pixels. Information about the results of scheduled jobs can be obtained in several ways.
EXPORT FROM THE CONSOLE
The context menu of a job in the Job Results section has an Export Job Results.. item. This gives you some options, and it creates a command line for you with all the corresponding parameters you choose here. Either click Export or copy the command line and invoke that elsewhere. Either way you end up with an XML file containing job result information. Although all the information you could possibly need is in this file, there are several problems. This file can get quite big and while there is also an option to export the results per agent, that means you now need to parse lots of individual files. Also, Exporting from the console is a blocking operation. Annoying!
EXPORT FROM WEBAPI
The same xml export can be done via the WebAPI using the ExportJobResults operation. This takes three parameters, jobId, includeOverview and includeDetailed which do what you expect. The response will include the same xml as you would get via the console but it is base64 encoded. The reason for this is that the http response is encoded as utf-8, but the enclosed job results xml has utf-16 specified as its encoding. Instead of properly adjusting the xml declaration of the job results, they chose to base64 encode it to prevent xml parsers downstream to throw an error.
EXPORT WITH BUILT-IN TASK
At last there is also a built in task named Export RES Automation Manager Job Results on which the admin guide states:
“With Export RES Automation Manager Results, you can export Job results to XML files. This allows you to backup Job results for review purposes. This Task is especially useful in combination with the Task Delete RES Automation Manager Results, in which you first back up certain Job results by exporting them to zipped XML files, and then clean up the Datastore by deleting them.”
Unfortunately it is not possible to pass in some sort of an identifier (GUID) for a specific job to export the result of. In stead it is only possible to do bulk exports; you will end up with a zip file with (potentially lots of) xml files and each filename is the GUID of that job. I can imagine this would be useful in some scenarios, as described in the admin guide, but I haven’t had much use for it yet.
Job statistics with Powershell
That’s it, there seems to be no way to get simple job statistics other than clicking and viewing them in the console. The WebAPI has an operation called GetJobUsageReport but this only shows overall job status. If you are interested in the details of tasks and agents you will need to export the entire job results and do some statistics on that. You can load the Export.xml in Powershell and do something like this:
[XML]$results = Get-Content('.\Export.xml')
$tasks = $results.SelectNodes('//task')
foreach ($task in $tasks)
{
$task.description
$xpath = '//task[guid/text()="' +
$task.guid +
'"]/results/agent/result/status'
$results.SelectNodes($xpath) |
Group {$_.'#text'} |
Format-Table -AutoSize -Property Count,Name -HideTableHeaders
}Which would give you output similar to this:
Download 23.6 KB in 1 file(s) to "%TEMP%"
172 Completed
4 Failed (job stopped)
Execute "%windir%\SysWoW64\cmd.exe /c cscript //NoLogo @[SCRIPT]"
70 Skipped
102 Completed
4 Cancelled
Execute "cscript //NoLogo @[SCRIPT]"
70 Completed
102 Skipped
4 Cancelled
Now this is all very nice, you can play around with the Xpath expression a bit to have it suit your needs and adjust the formatting if you like. There are however situations when this approach is not practical. Exporting the entire job results to xml can be costly with large jobs. If you run a decent sized project on a large number of machines, with tasks spitting out some data to stdout or in a grabbed log file, exporting takes a long time, and your database server takes quite a hit. Then you will need to import this xml into Powershell, have you ever tried loading a 200 MB xml file? I have, and on pretty decent machines there will be plenty of time for coffee.

Job statistics with SQL
Why don’t we skip the middleman? All information is in the datastore, just get it straight from the source. With the knowledge gained from previous explorations in the datastore this should be a breeze right?
JOBS VS MASTERJOBS
The tblMasterJob table stores information on all “MasterJobs”, but a Run Book consisting of multiple “jobs” is also considered a MasterJob. You can see this in the Job Results pane where you can select to “Show jobs contained in Run Books”. It corresponds with the ysnIsRuBookJob column. Let’s see how the console requests this information when we select the Job Results pane:
SELECT imgWho, MasterJobGUID, strDescription, dtmStartDateTime, dtmStopDateTime, strWho, ysnIsTeam, lngStatus, lngJobInvoker, ysnIsRunBook, ysnIsRunBookJob
FROM tblMasterJob
WHERE ysnObsolete = 0
AND lngStatus <> -1
AND lngStatus <> 0
AND lngStatus <> 1
AND lngStatus <> 2
AND dtmStopDateTime >= '1899-12-30T00:00:00'
AND ysnIsRunBookJob = 0
ORDER BY dtmStartDateTime DESCThis can be a bit confusing at first, and I feel this should be dealt with outside of our query. For now we assume we have a MasterJobGUID which is not a Run Book but rather an actual job (i.e. project/module scheduled to some target). From experience and deliberate testing I know the lngStatus will never be lower than -1 (disabled). The 0 means scheduled, 1 and 2 are for active and aborting respectively. All other values are some sort of status of a finished job, completed (4), failed (5), completed with errors (8) etc. This enumeration seems to be used in several places throughout. Why not just
lngStatus > 2
FROM MASTERJOB TO JOBS
For every Agent that runs tasks in a job (MasterJob), there is a corresponding entry in the tblJobs table. If you open a (master-)job result in the console it will execute a couple of queries. One of them pulls information from the tblAgents and tblTeams tables to pretty print the target names. Another query pulls in data from the tblJobStats table. Wait?! JobSTATS! That sounds like what we are after here, so what is in there exactly? There seems to be an entry for every task executed on every agent along with a status code. Unfortunately the tasks are identified by a GUID, and that GUID is not stored directly in a table somewhere.
TASK INFORMATION
For existing modules it is stored in the imgTasks binary xml thing column, but because a module may have changed, the MasterJob also holds an imgTasks binary xml thing (maybe I should think of a better name for this) which has the information of all the tasks at execution time. They are essentially the same, but the MasterJob version adds some information which the Module version stores separately in columns. Every(!) entry in the tblJobs table also has this imgTasks column and it has all of this information (again) but now information about the job results are added. Disk space is cheap, or so it seems. Here is an example imgTasks xml thing from the tblJobs table:
<?xml version="1.0" encoding="UTF-16"?>
<tasks MasterJobGUID="{55D1E5FD-CD92-481E-ABDB-62ED86288D1F}"
JobGUID="{B6FE9417-7FE7-463F-8EB4-AEF2847B4CA9}"
AgentGUID="{3CCBDB70-2391-46D5-B2AF-6CDF197D0427}">
<task hidden="yes" moduleinfo="yes">
<delusedres>yes</delusedres>
<limitinvoke>no</limitinvoke>
<parameters identifier="{E7ECFF2D-DC8C-4DA4-A790-120808580B6C}" />
<conditions>
<condition guid="{4275F9FA-1953-45F4-9D3E-1C707449A347}">
<expressions />
<operator>AND</operator>
<actiontrue>3</actiontrue>
<when>0</when>
<action>3</action>
<enabled>yes</enabled>
</condition>
</conditions>
<moduleinfo>
<guid>{5CF59E5A-343C-4D85-A83C-8B18E4731040}</guid>
<name>Example - Show Hostname</name>
<description />
</moduleinfo>
</task>
<task MasterJobGUID="{55D1E5FD-CD92-481E-ABDB-62ED86288D1F}"
JobGUID="{B6FE9417-7FE7-463F-8EB4-AEF2847B4CA9}"
AgentGUID="{3CCBDB70-2391-46D5-B2AF-6CDF197D0427}"
AgentName="WIN-TTDNUBI9TNA" Status="4">
<properties>
<type>COMMAND</type>
<guid>{4275F9FA-1953-45F4-9D3E-1C707449A347}</guid>
<description>Execute "C:\Windows\SYSTEM32\hostname.exe"</description>
<enabled>yes</enabled>
<comments />
<onerror>fail</onerror>
</properties>
<settings>
<commandline>C:\Windows\SYSTEM32\hostname.exe</commandline>
<username />
<password encrypted="yes" />
<loaduserprofile>no</loaduserprofile>
<usecmd>yes</usecmd>
<redirect>yes</redirect>
<failonerroutput>no</failonerroutput>
<validateexitcode>no</validateexitcode>
<validateexitcode>no</validateexitcode>
<failifexitcode>no</failifexitcode>
<exitcodes>0</exitcodes>
<timeout>10</timeout>
<terminate>no</terminate>
<terminatetree>no</terminatetree>
<grablogfile />
<script />
<scriptext>cmd</scriptext>
</settings>
<Log>{8DA3E076-23D0-493E-ABE2-745F91DC4B0E}</Log>
<result>Completed</result>
</task>
</tasks>Well, slap my ass and call me Sally! Every bit of information we need (and then some) is in this single .. eh whatever you want to call it. Why oh why is this information stored this way? I can think of many situations where you ditch well known principles (Normalization, DRY, column type selection etc etc) for the sake of performance. But in this case it seems to be resulting in a performance penalty! The more I investigate the inner workings, the more I understand why exactly this product does not scale well.
DATA MODELING FOR CONNOISSEURS
Whose brilliant idea was it to represent projects (not shown in this example), modules, and tasks all as “task” elements using these moduleinfo=”yes” and projectinfo=”yes” attributes?! The only way to figure out which task is part of which module, and which module is part of which project, and their respective execution order, is to look at the ordering of all these tasks elements. They are fundamentally different types of objects in the application! Why not properly map them to a nested structure in XML? and why this dependency on element ordering? I think this comment on StackExchange put it nicely (regarding a similar situation):
The obvious thing to do in situations like this is to find the developer who wrote that class and beat him. This is rarely possible, though it’s interesting to contemplate a world in which it were.
But let’s look at the bright side, at least there is plenty room for improvement.. now on with the show.
LET’S JUST QUERY THE TBLJOBS TABLE
The “status” attribute in the /tasks/task element is that same thing that is stored in the tblJobStats table, but often we are also interested in this /tasks/task/result value. Whenever a task failed for some reason this usually holds a more meaningful error message. It shows up like this when you drill down in the gui:

The plan is to select all entries in the tblJobs table, filter for the MasterJobGUID we want to report on, transform the imgTask binary XML thing to something query-able, and enjoy detailed job statistics. So let’s roll up our sleeves and do exactly that. One step at a time.
--Set MasterJobGUID here
DECLARE @MJGUID UNIQUEIDENTIFIER
SET @MJGUID = '{578CA05A-3EC8-434C-8CAD-1B086757C2DE}'
-- A lookup table to translate status codes into something more readable
-- this mght be improved to allow for slight differences between the
-- status codes for different types of objects. Or just removed.
DECLARE @StatusCode TABLE
(id INT NOT NULL PRIMARY KEY,
statusmessage VARCHAR(30))
INSERT INTO @StatusCode (id, statusmessage)
VALUES (-1, 'Disabled')
, (0, 'Scheduled')
, (1, 'Active')
, (2, 'Aborting')
, (3, 'Aborted')
, (4, 'Completed')
, (5, 'Failed')
, (6, 'Failed (job stopped)')
, (7, 'Cancelled')
, (8, 'Completed with errors')
, (9, 'Skipped')
, (10, 'Pending')
, (11, 'Timeout')So far so good, we set a MasterJobGUID (get that from however you please) and a translation table for the status codes. The plan is now to query that imgTasks thing from the tblMasterJob table once. After all, modules and projects don’t change during execution, the taskGUID is consistent throughout so if we can stick it in a temporary table then we can join them later.
--Build taskstructure table from MasterJob table
--This is the Tasks(XML) which has the same description
DECLARE @TaskStructure TABLE (
ProjectGUID UNIQUEIDENTIFIER,
ProjectName VARCHAR(50),
ModuleGUID UNIQUEIDENTIFIER NOT NULL,
ModuleName VARCHAR(50) NOT NULL,
ModuleDescription VARCHAR(50) NOT NULL,
ModuleOrder INT,
TaskGUID UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL,
TaskDescription VARCHAR(50) NOT NULL,
TaskComments VARCHAR(500) NOT NULL,
TaskType VARCHAR(50),
TaskOrder INT)So how do we fill this table? We will have to step through the task nodes in that piece of xml, after we triple cast it back to xml, so the obvious weapon of choice is a cursor.
DECLARE @TaskCursor CURSOR
SET @TaskCursor = CURSOR FOR
SELECT T.C.query('(.)') AS TaskXML
FROM (SELECT CAST(
CAST(
CAST(imgTasks AS VARBINARY(MAX))
AS NVARCHAR(MAX)) AS XML) AS MJTasks
FROM tblMasterJob tMJ
WHERE MasterJobGUID = @MJGUID
) TXML
CROSS APPLY TXML.MJTasks.nodes('/tasks/task') AS T(C)
DECLARE @TaskNode XML
DECLARE @ProjectGUID UNIQUEIDENTIFIER
DECLARE @ProjectName VARCHAR(50)
DECLARE @ModuleGUID UNIQUEIDENTIFIER
DECLARE @ModuleName VARCHAR(50)
DECLARE @ModuleDescription VARCHAR(50)
DECLARE @ModuleOrder INT
DECLARE @TaskGUID UNIQUEIDENTIFIER
DECLARE @TaskDescription VARCHAR(50)
DECLARE @TaskComments VARCHAR(500)
DECLARE @TaskType VARCHAR(50)
DECLARE @TaskOrder INTSo with our variable all set, we initialize the counter to keep track of the ordering of the modules and fill this bastard.
SET @ModuleOrder = -1
OPEN @TaskCursor
FETCH NEXT FROM @TaskCursor INTO @TaskNode
WHILE @@FETCH_STATUS = 0
BEGIN
IF @TaskNode.value('(/task/@projectinfo)[1]', 'varchar(5)') = 'yes'
BEGIN
SET @ProjectGUID = @TaskNode.value('(/task/projectinfo/guid)[1]', 'UNIQUEIDENTIFIER')
SET @ProjectName = @TaskNode.value('(/task/projectinfo/name)[1]', 'varchar(50)')
END
IF @TaskNode.value('(/task/@moduleinfo)[1]', 'varchar(5)') = 'yes'
BEGIN
SET @ModuleGUID = @TaskNode.value('(/task/moduleinfo/guid)[1]', 'UNIQUEIDENTIFIER')
SET @ModuleName = @TaskNode.value('(/task/moduleinfo/name)[1]', 'varchar(50)')
SET @ModuleDescription = @TaskNode.value('(/task/moduleinfo/description)[1]', 'varchar(50)')
SET @ModuleOrder = @ModuleOrder + 1
SET @TaskOrder = 0
END
IF @TaskNode.exist('(/task/@hidden)') = 0
BEGIN
SET @TaskGUID = @TaskNode.value('(/task/properties/guid)[1]', 'UNIQUEIDENTIFIER')
SET @TaskDescription = @TaskNode.value('(/task/properties/description)[1]', 'varchar(50)')
SET @TaskComments = @TaskNode.value('(/task/properties/comments)[1]', 'varchar(500)')
SET @TaskType = @TaskNode.value('(/task/properties/type)[1]', 'varchar(50)')
INSERT INTO @TaskStructure
VALUES(@ProjectGUID,
@ProjectName,
@ModuleGUID,
@ModuleName,
@ModuleDescription,
@ModuleOrder,
@TaskGUID,
@TaskDescription,
@TaskComments,
@TaskType,
@TaskOrder)
SET @TaskOrder = @TaskOrder + 1
END
FETCH NEXT FROM @TaskCursor INTO @TaskNode
ENDNow we grab a bit more information than we would need, strictly speaking, but I think we can use this principle for more than just job statistics. So now we have our lookup tables for status codes and for every task we can lookup where it belongs in the Project/Module/Task structure, with proper ordering added. Another benefit is that the task description is actually changed in some cases from the xml in the tblMasterJob as variables are parsed upon execution. That’s not helpful at all later on, so good to have a consistent Task Structure table.
CAN WE FINALLY START QUERYING RESULTS, SHEEZ!
Almost, since we want to do joins on values that are hidden within xml in binary image fields and other such wizardry, we need to create a more sane table first to do that with. Some limitations in SQL Server, as well as the TSQL-Fu of yours truly.
-- A temporary table to take care of all this CAST CAST CAST nonsense
DECLARE @JobTable TABLE (
JobGUID UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL,
MasterJobGUID UNIQUEIDENTIFIER NOT NULL,
AgentName VARCHAR(50) NOT NULL,
JobOrder INT NOT NULL,
TasksXML XML NOT NULL,
JobStatus INT NOT NULL)
INSERT INTO @JobTable
(JobGUID,
MasterJobGUID,
AgentName,
JobOrder,
TasksXML,
JobStatus)
SELECT JobGUID,
MasterJobGUID,
strAgent,
lngOrder,
CAST(
CAST(
CAST(imgTasks AS VARBINARY(MAX))
AS NVARCHAR(MAX))
AS XML),
lngStatus
FROM tblJobs
WHERE MasterJobGUID = @MJGUID
ORDER BY lngOrder;Honestly, I am unsure if we can skip this step. I could not get it to work early on without it, and after a while decided that it is probably best to leave it as such. It makes the next query slightly more readable. We now have this JobTable with the XML data in an actual XML column. One more pass to sanitize this XML into proper columns of the possibly interesting information.
-- Now we can grab all the task output from this xml
WITH SanitizedJobStats AS
(SELECT AgentName,
JobOrder,
JobStatus,
t1.task.value('(properties/guid)[1]', 'UNIQUEIDENTIFIER') AS TaskGUID,
t1.task.value('(@Status)[1]', 'INT') AS TaskStatus,
t1.task.value('(Log)[1]', 'VARCHAR(50)') AS OutputLog,
t1.task.value('(GrabbedLog)[1]', 'VARCHAR(50)') AS GrabbedLog,
t1.task.value('(result)[1]', 'VARCHAR(50)') AS Result,
t1.task.value('(properties/description)[1]', 'VARCHAR(50)') AS Description
FROM @JobTable j
CROSS APPLY j.TasksXML.nodes('/tasks/task[not(@hidden)]') As t1(task)
)This is called a Common Table Expression (apparently) and suits our needs just fine. We select all non hidden tasks (a.k.a. tasks) and pick out some of the fields. The Outputlog and Grabbedlog are not used right now, but can be useful later on. They contain a pointer to the tblLogs table which has a pointer to the tblFiles table where the actual output of stdout, stderr and any grabbed log files are stored. I digress, query this thing for fsck sake:
SELECT AgentName,
jobOrder,
js.statusmessage AS JobStatus,
tstruct.ModuleOrder,
tstruct.ModuleName,
tstruct.ModuleDescription,
tstruct.TaskOrder,
tstruct.TaskType,
tstruct.TaskDescription,
tstruct.TaskComments,
ts.statusmessage AS TaskStatus,
--I noticed linebreaks in this field
--They kind of screw with copy paste so get rid of 'em
REPLACE(Result, CHAR(10),'') As Result
FROM SanitizedJobStats sjs
LEFT JOIN @StatusCode js ON sjs.JobStatus = js.id
LEFT JOIN @StatusCode ts ON sjs.TaskStatus = ts.id
LEFT JOIN @TaskStructure tstruct ON sjs.TaskGUID = tstruct.TaskGUID
--Ordering not strictly necessary
ORDER BY tstruct.ModuleOrder,
tstruct.TaskOrder
-- Phew!I think we made it! (I doubt anyone will ever get this far in the article) but what was the whole point of this again? Job statistics. So with this, and a bit of Excel pivot table magic we can now turn this un-copyable, un-analysable, RSI generator in the console:
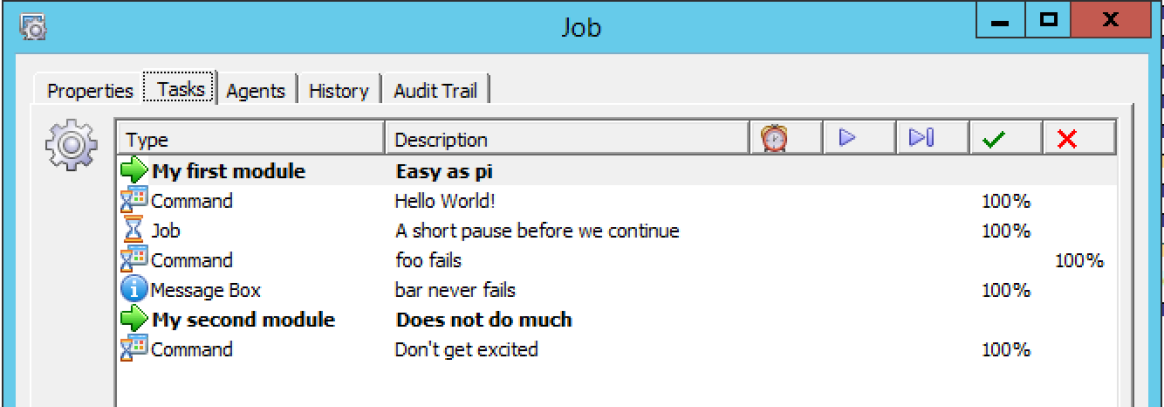
into something like this:
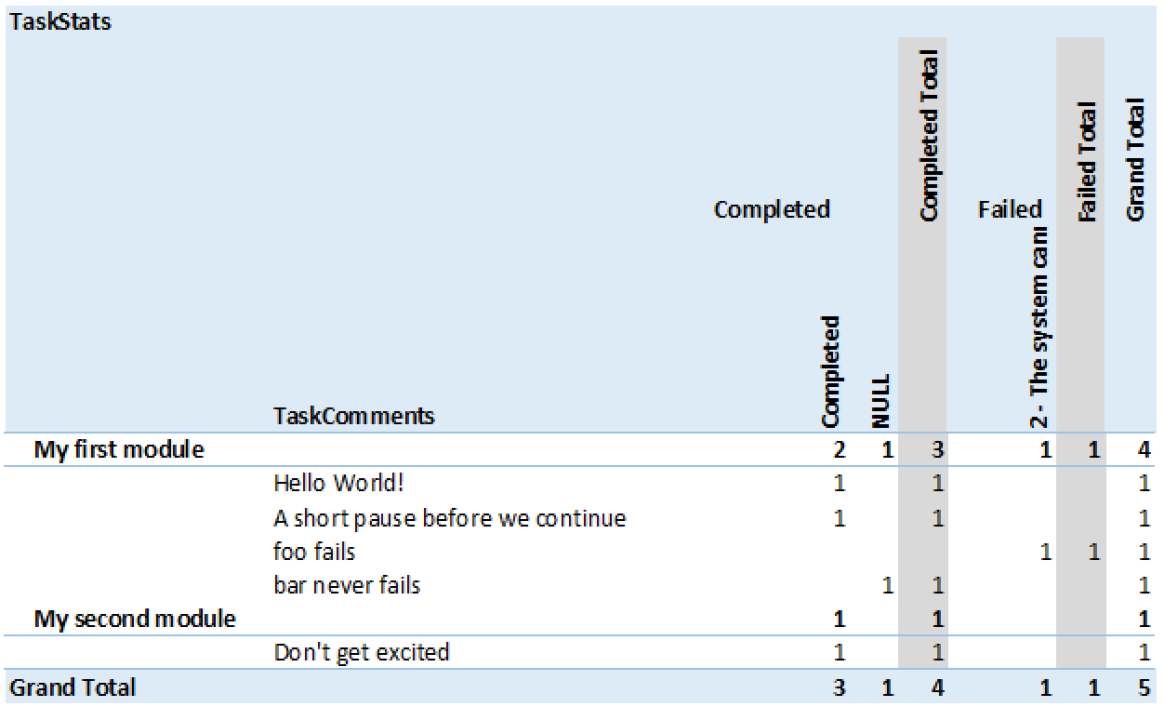
Now with a small job like in the example, executed on a single machine, this may seem totally insignificant. Maybe it is, but if you run a project with 20 something tasks, on a couple of thousand machines this is golden if you ask me. You can have a nice pivot table, or do additional querying in SQL. Never again locked out of the console for 20 minutes, to end up with a barely parsable XML monster.

Anyone who actually wants to try this out, just cut and paste all the bits I posted because wordpress won’t let me upload .sql (or .txt or .zip or whatever) files. I have looked around a little, hoping to find timing information per task (as opposed to per module). That would give some incredible possibilities for analyzing the performance of your modules but I think it is not saved anywhere. I will probably just use it occasionally for troubleshooting, either a project, or the RES infrastructure. In theory you could put some triggers on the database and store this stuff more permanently and feed it automatically into some sort of reporting/monitoring solution. Then again, perhaps it would better to use software that you don’t have to fix yourself in so many ways.